네이버 영화평
사전준비
- ratings_small : 네이버 영화 자료로 id, 리뷰내용, 긍정과 부정을 구분하는 이진 데이터가 들어있다.
- 사용 도구 : 구글 코랩, JPype, rhinoMorph, matplot,Keras
먼저 자바와 자바와 파이썬을 연결하기위한 JPype 그리고 형태소 분석을 위한 rhinoMorph 설치 코드 입니다.
!apt-get update
!apt-get install g++ openjdk-8-jdk
!pip install JPype1
!pip install rhinoMorph
코랩 한글 깨짐 방지
코랩에서는 그래프를 그리거나 워드 클라우드시 한글 깨짐 현상이 발생하는데 방지하기 위한 코드입니다.
import matplotlib as mpl
import matplotlib.pyplot as plt
%config InlineBackend.figure_format = 'retina' # 폰트가 깨끗하게 보이도록 설정
!apt install fonts-nanum # 나눔 폰트 설치
import matplotlib.font_manager as fm
fontpath = '/usr/share/fonts/truetype/nanum/NanumMyeongjo.ttf'
font = fm.FontProperties(fname=fontpath, size=9)
# 기본 글꼴 변경
import matplotlib as mpl
mpl.font_manager._rebuild()
mpl.pyplot.rc('font', family='NanumMyeongjo')
데이터 읽어오기
-
cd ‘/content/drive/MyDrive/pytest’로 경로를 옮겨 줍니다.
-
다음 코드는 데이터를 읽고 쓰기위한 코드 입니다.
def read_data(filename, encoding='cp949'): # 읽기 함수 정의
with open(filename, 'r', encoding=encoding) as f:
data = [line.split('\t') for line in f.read().splitlines()]
data = data[1:] # txt 파일의 헤더(id document label)는 제외하기
return data
def write_data(data, filename, encoding='cp949'): # 쓰기 함수도 정의
with open(filename, 'w', encoding=encoding) as f:
f.write(data)
ratings = read_data('ratings_small.txt')
네이버 형태소 분리하기
- 형태소 분석을 위한 rhinoMorph를 선언해준다.
import rhinoMorph
rn = rhinoMorph.startRhino()
- 네이버 영화평 형태소 분리하기
# 형태소가 분석된 내용과 id,label을 저장하기 위한 변수이다.
morphed_data = ''
for data_each in ratings:
morphed_data_each = rhinoMorph.onlyMorph_list(rn, data_each[1], pos=['NNG', 'NNP', 'VV', 'VA', 'XR', 'IC', 'MM', 'MAG', 'MAJ'], eomi= True)
joined_data_each = ' '.join(morphed_data_each) # 문자열을 공백을 두고 하나로 연결
if joined_data_each: # 내용이 있는 경우만 저장하게 함
morphed_data += data_each[0]+"\t"+joined_data_each+"\t"+data_each[2]+"\n"
# 형태소 분석된 파일 저장
write_data(morphed_data, 'ratings_morphed.txt', encoding='cp949')
# 형태소가 분석된 파일을 불러온다.
mor = read_data('ratings_morphed.txt')
내용부분과 감정부분 가져오기
# 감정부분 data[2]에 0(부정)과 1(긍정)로 감정이 저장되어있다.
data_senti = [data[2] for data in mor]
data_text = [data[1] for data in mor]
Tokenizer
%tensorflow_version 2.x
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
import numpy as np
import math
validation_ratio = math.floor(len(data_text) * 0.3) # 최적 모델 판정을 위한 검증 샘플은 전체의 30%로 한다
max_words = 10000 # 데이터셋에서 가장 빈도 높은 9,999 개의 단어만 사용한다
maxlen = 200 # 항상 각 문장의 길이가 200 단어가 되도록 고정한다
tokenizer = Tokenizer(num_words=max_words) # 상위빈도 max_words 개의 단어를 추려내는 Tokenizer 객체 생성
tokenizer.fit_on_texts(data_text) # texts 내용에 대한 단어 인덱스를 구축한다. 사용할 단어가 결정된다
word_index = tokenizer.word_index
data = tokenizer.texts_to_sequences(data_text) # 여기서 9,999 개의 단어만 추출된다.
one-hot encoding
def one_hot(sequences,dimension):
# sequences의 길이와 dimension의 길이 만큼 0으로 채운 행렬을 생성한다.
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
data = one_hot(data,dimension=max_words)
labels = data_senti #타겟 변수 설정
train데이터와 test데이터 분리
- x데이터와 y데이터 랜덤하게 섞어주기
import numpy as np
indices = np.arange(data.shape[0]) # data.shape[0](494개) 만큼 숫자를 생서어해준다.
np.random.shuffle(indices) # 생성한 숫자를 랜덤하게 섞어준다.
labels.np.asarray(labels).astype('float32') # data가 np.array이므로 labels도 똑같이 바꿔준다.
data = data[indices] # 랜덤하게 섞어준다
labels = labels[indices]
- 훈련데이터와 테스트데이터 분리하기
x_train = data[validation_ratio:] # 훈련데이터의 70%를 훈련데이터
y_train = labels[validation_ratio:] # 훈련데이터의 70%를 훈련데이터 Label (data와 labels는 같은 순서)
x_val = data[:validation_ratio] # 훈련데이터의 30%를 검증데이터
y_val = labels[:validation_ratio]
Layer 쌓기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential() # 모델을 새로 정의
model.add(Dense(64, activation='relu', input_shape=(max_words,))) # 첫 번째 은닉층. activation은 다음 층으로 값을 넘기는 방법
model.add(Dense(32, activation='relu')) # 두 번째 은닉층
model.add(Dense(1, activation='sigmoid'))
Complie model and 데이터 학습
# compile
model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['acc'])
# 모델 학습하기
history = model.fit(x_train, y_train, epochs=11, batch_size=32, validation_data=(x_val, y_val))
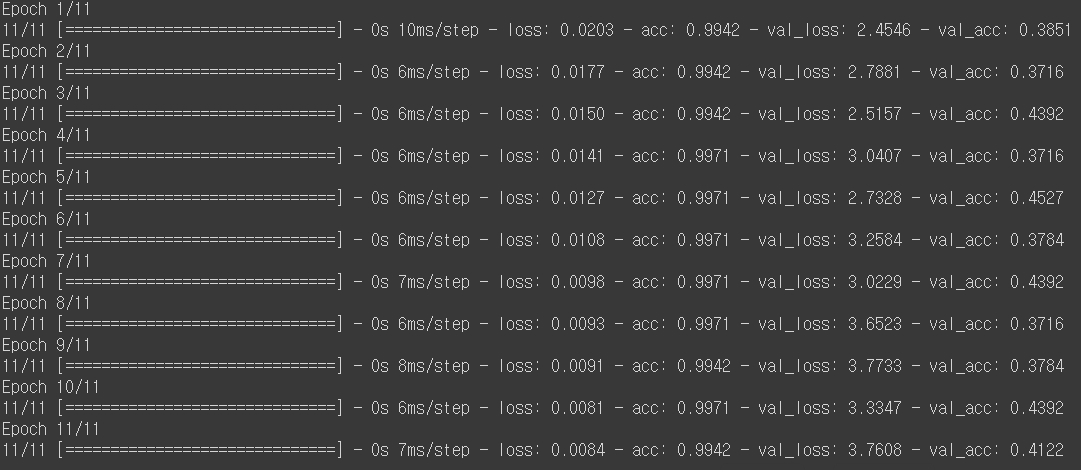
위의 사진에서 볼 수 있듯이 epoch 5에서 가장 좋은 성능을 보인다.
Accuracy & Loss 확인
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
print('Accuracy of each epoch:', acc) # [0.79, 0.90, 0.93, 0.94, 0.96, 0.97, 0.98, 0.98, 0.98, 0.99]
epochs = range(1, len(acc) +1)
Plotting Accuracy
- accuracy ploting
import matplotlib.pyplot as plt
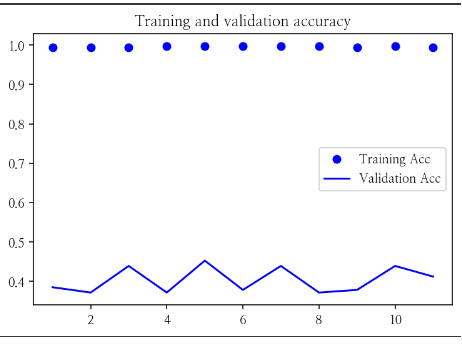
# 훈련데이터의 정확도에 비해 검증데이터의 정확도는 낮게 나타난다
# epoch가 늘어나면 모델은 훈련데이터에 매우 민감해져(과대적합) 오히려 새로운 데이터를 잘 못 맞춘다
plt.plot(epochs, acc, 'bo', label='Training Acc')
plt.plot(epochs, val_acc, 'b', label='Validation Acc')
plt.title('Training and validation accuracy')
plt.legend()
- loss ploting
plt.figure() # 새로운 그림을 그린다
# 훈련데이터의 손실값은 낮아지나, 검증데이터의 손실값은 높아진다
# 손실값은 오류값을 말한다. 예측과 정답의 차이를 거리 계산으로 구한 값이다
plt.plot(epochs, loss, 'bo', label='Training Loss')
plt.plot(epochs, val_loss, 'b', label='Validation Loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
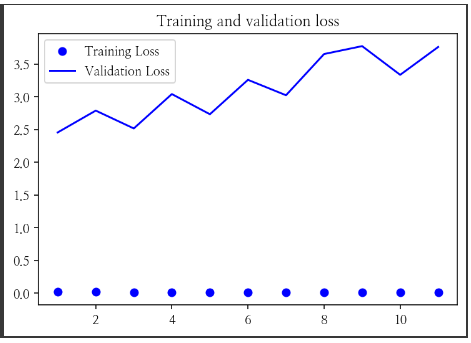
가장 좋은 성능을 보인 epochs 적용
epoch가 5에서 가장 좋은 성능을 보였으므로 모델에 epochs를 5를 적용한 후 결과를 살펴보자.
history = model.fit(x_train, y_train, epochs=5, batch_size=32, validation_data=(x_val, y_val))

빈도분석
영화 리뷰평에서 가장 많이 나온 단어를 분석하는 과정이다.
Counter는 리스트의 구성요소를 종류별로 빈도 계산한다.
from collections import Counter
# data_text는 공백으로 연결되어있으므로 분리해주는 작업을 해준다
merge_text = ' '.join(data_text)
merge = merge_text.split(' ')
freq = Counter(merge)
시각화
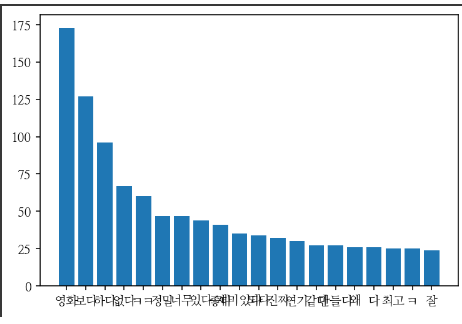
- 그래프로 가장 빈도가 높은순으로 알아보자
graph_labels=sorted(freq.values(),reverse=True)
graph_x = sorted(freq,key=freq.get,reverse=True)
plt.bar(range(20),graph_labels[:20])
plt.xticks(range(20),graph_x[:20])
plt.show()
- 결과
- wordcloud로 한눈에 알아보자
!pip install wordcloud # 워드클라우드 패키지 설치
from wordcloud import WordCloud
cloud = WordCloud(font_path=fontpath, width=800, height=600).generate(" ".join(graph_x))
plt.imshow(cloud, interpolation='bilinear') # 글자를 더 부드럽게 나오게 한다
plt.axis('off') # 축의 위치 정보 off
plt.show()

Leave a comment