자연어처리(워드 임베딩)
Word Embbedding
- 워드 임베딩은 단어를 숫자로 바꾸는 기법 중 하나이다.
- 특정 단어의 주변의 단어를 이용하여 유사도 즉 숫자로 단어를 대체한다.
- 예) 개와 사료는 한 문장의 주변에 등장하는 비율이 키조개보다 높으므로 더욱 유사하다.
- 워드 임베딩 방법론으로는 LSA, Word2Vec, FastText,Glove등이 있다.
- 원-핫 인코딩은 고차원이고 값의 타입이 1과 0인 반면에 임베딩 벡터는 저차원이고 실수로 구성되어있다.
Word2Vec
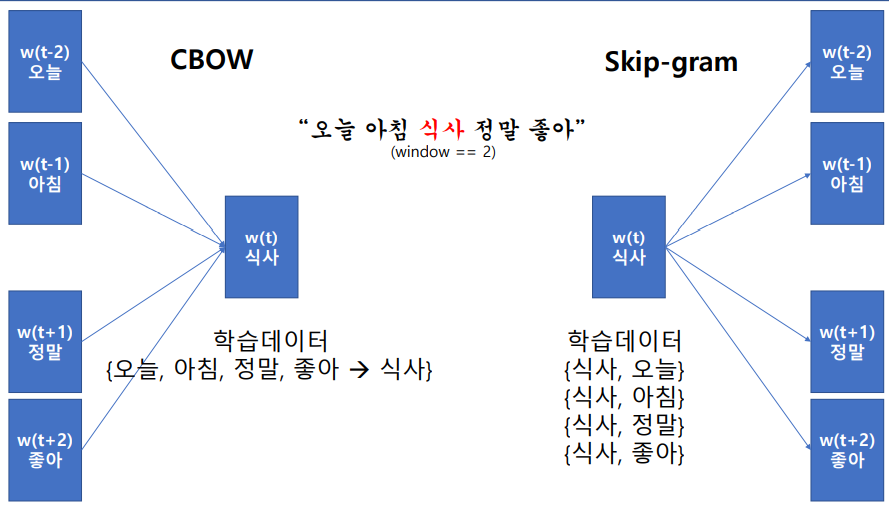
Word2Vec은 CBOW와 Skip-gram이라는 두개의 하위 모델이 있다 CBOW는 주변에 있는 문맥 단어로 타깃 단어 하나를 예측하는 방법이고, Skip-gram은 타깃 단어를 가지고 주변 문맥 단어를 예측한다. Skip-gram의 임베딩 품질이 CBOW보다 좋은 경향이 있다.
학습할 텍스트 읽기
import os.path
embedding_dim = 50 # 임베딩 차원수 설정
filepath = '/content/gdrive/My Drive/pytest/'
os.chdir(filepath) # 경로 설정
print("Current Directory:", os.getcwd())
with open('wiki_test.txt', 'r', encoding='utf-8') as f: # 테스트용 파일 읽기
data = f.read()
문장단위 분리 및 형태소분석기 기동
import rhinoMorph
from nltk.tokenize import sent_tokenize
import nltk
nltk.download('punkt')
sent_data = sent_tokenize(data) # 문장 단위 분리(tokenizer와 달리 문장 단위로 분리해준다.)
rn = rhinoMorph.startRhino() # RHINO 기동
print('type:', type(sent_data))
print('length:', len(sent_data)) # 전체 문장의 개수
print('sentence sample:', sent_data[:20])
텍스트의 형태소 분석
total_lines = len(sent_data)
cnt = 0
with open(filepath+'word2vec/wiki202003_nationalcorpus_naverratings_morphed.txt', 'w', encoding='utf-8') as f:
for data_each in sent_data:
morphed_data_each = rhinoMorph.onlyMorph_list(rn, data_each, pos=['NNG', 'NNP', 'NP', 'VV', 'VA', 'XR', 'IC', 'MM', 'MAG', 'MAJ'])
joined_data_each = ' '.join(morphed_data_each)
if joined_data_each:
f.write(joined_data_each + '\n')
cnt += 1
if (cnt % 1000) == 0: # 진행 정도 확인을 위해 1000번째 문장마다 확인
print(round(cnt/total_lines * 100, 3), '%')
print('Morphological Analysis Completed.')
형태소 분석 결과를 읽어 리스트로 만들기
def read_data(filename, encoding='utf-8'): # 읽기 함수 정의
with open(filename, 'r', encoding=encoding) as f:
data = [line.split(' ') for line in f.read().splitlines()]
return data
data = read_data(filepath+"word2vec/wiki202003_nationalcorpus_naverr
atings_morphed.txt", 'utf-8’)
print(len(data))
print(type(data))
print(data[:3])
Word2Vec-임베딩 구성
from gensim.models import Word2Vec
os.chdir(filepath+'word2vec/')
# size: 벡터의 차원, window: 컨텍스트 윈도우의 크기, min_count: 단어 최소 빈도, workers: 학습을 위한 프로세스 수, sg: 0은 CBOW, 1은 skip-gram
model = Word2Vec(sentences=data, size=embedding_dim, window=10,
min_count=5, workers=4, sg=1)
model.save('embedding_window10_mincnt5_skipgram.model')
print('Completed.')
Word2Vec-임베딩 값 저장
words = list(model.wv.vocab) #model에 구성된 워드임베딩을 리스트 형태로 불러온다.
with open('embedding_window10_mincnt5_skipgram.txt', 'w') as f:
for word in words:
data = model.wv[word].tolist() # 현재 단어의 임베딩 값을 가져온다
print('data_pre:', data) # 현재 단어의 임베딩 값을 출력해본다
data.insert(0, word) # 시작 부분에 해당 단어를 넣는다
print('data_after:', data) # 현재 단어의 이름과 함께 임베딩 값을 출력해본다
for item in data: # 단어 이름부터 시작하여 각 벡터의 값을 저장한다
f.write("%s " % item)
f.write("\n")
유사어 찾기
model = Word2Vec.load('embedding_window10_mincnt5_skipgram.model')
print('--- 유사단어 출력 ---')
similarWords = model.wv.most_similar(positive=['행복', '웃음', '밝'], topn=3)
print(similarWords) # [('흐뭇', 0.8801068067550659), ('마음', 0.8738192319869995), ('해맑', 0.8424177169799805)]
word = []
for similarWord in similarWords: # 유사도값을 제외하고 단어만 모은다
word.append(similarWord[0])
print(word) # 흐뭇,마음,해맑이 나온다.
두 단어 사이의 유사도 계산
model.wv.similarity(‘한국’,’일본’) 0.8 model.wv.similarity(‘한국’,’미국’) 0.7 model.wv.similarity(‘한국’,’중국’) 0.6
Leave a comment