자연어처리(감성분석)
사전을 이용한 감성분석
- 문서에서 긍정적 단어가 나타나면 +1, 부정적 단어가 나타나면 -1을 쓰는 것과 같은 방법
- 감성점수 >0 이면 긍적적 문서, < 0 이면 부정적 문서, = 0 이면 중립적인 문서로 본다.
- sigmoid 함수를 사용하여 0~1 사이로 정규화 하는 방법도 있다.
감정어의 종류
- 감정어 : 말하는 이의 감정을 주관적으로 표현하는 것으로서 극성이 잘 바뀌지 않음 예) 화나다, 즐겁다, 괴롭다, 슬프다
- 평가어 : 대상에 대한 감정을 시실적으로 평가하는 것으로서 맥락에 따라 극성이 바뀔 수 있음 예) 깨끗하다 “냉장고가 깨끗하다” 더럽다 “더럽게 깨끗하다” 약화하다 “고통을 약화하다”
감정분석
- 감정사전 읽기
data_id = [line[0] for line in data] # 데이터 id data_text = [line[1] for line in data] # 데이터 본문 data_senti = [line[2] for line in data] # 데이터 긍부정 부분 positive = read_data('positive.txt') # 긍정 감정사전 읽기 negative = read_data('negative.txt') # 부정 감정사전 읽기 pos_found = [] neg_found = [] -
감정단어 파악
def cntWordInLine(data, senti): senti_found = [] for onedata in data: oneline_word = onedata.split(' ') # 한 줄의 데이터를 공백 단위로 분리하여 리스트로 저장 senti_temp = 0 # 그 줄에서 발견된 감정단어의 수를 담는 변수 for sentiword in senti: # 감정사전의 어휘 if sentiword[0] in oneline_word: # sentiword[0] 하여 리스트 원소를 문자열로 추출 senti_temp += 1 # 현재의 감정단어와 일치하면 숫자를 하나 올려 줌 (중복X) senti_found.append(senti_temp) # 현재의 줄에서 찾은 감성단어의 숫자를 해당 위치에 저장 return senti_found data_senti_poscnt = cntWordInLine(data_text, positive) # 발견된 긍정 단어의 숫자 파악 data_senti_negcnt = cntWordInLine(data_text, negative) # 발견된 부정 단어의 숫자 파악 print(data_senti_poscnt[:20]) print(data_senti_negcnt[:20]) -
감정점수 계산
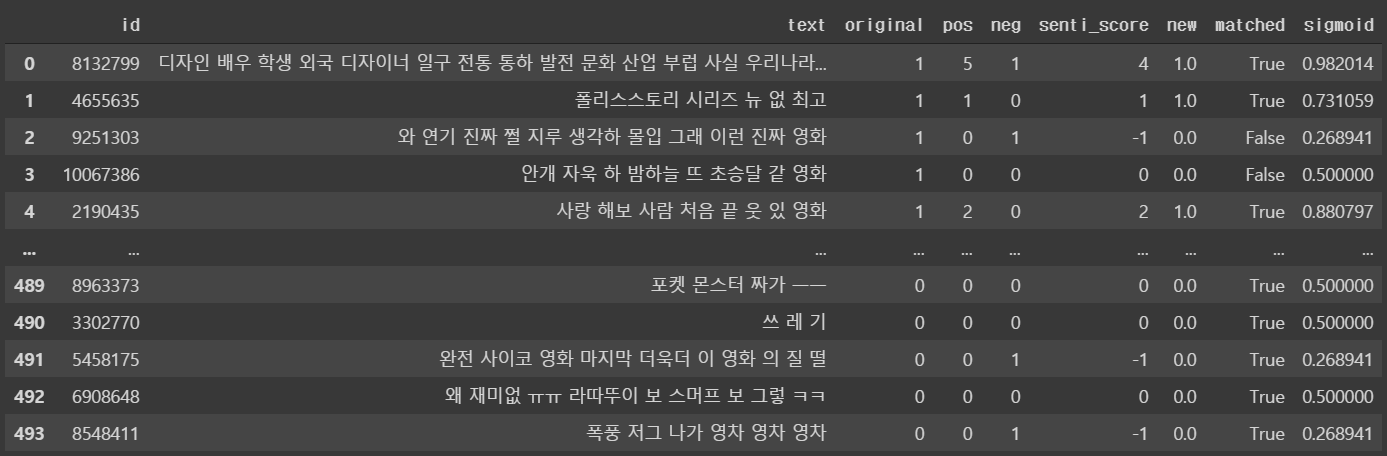
# Pandas 데이터프레임으로 저장 import pandas as pd newdata = pd.DataFrame({'id':data_id, 'text':data_text, 'original':data_senti, 'pos':data_senti_poscnt, 'neg':data_senti_negcnt}) senti_score = newdata['pos'] - newdata['neg'] # 긍정개수에서 부정개수를 뺌 newdata['senti_score'] = senti_score # 그 수를 senti_score 컬럼에 저장 newdata.loc[newdata.senti_score > 0, 'new'] = 1 # 새로운 긍부정 기호 newdata.loc[newdata.senti_score <= 0, 'new'] = 0 # 새로운 긍부정 기호 # 처음에 기록된 긍부정과 새로 계산된 긍부정이 같은지 여부를 matched 컬럼에 저장 # original 컬럼은 문자로 되어 있으므로 숫자로 변환 뒤 비교 newdata.loc[pd.to_numeric(newdata.original) == newdata.new, 'matched'] = 'True' newdata.loc[pd.to_numeric(newdata.original) != newdata.new, 'matched'] = 'False' -
원점수와 비교 및 저장
score = newdata.matched.str.count('True').sum() / (newdata.matched.str.count('True').sum() + newdata.matched.str.count('False').sum()) * 100 -
시그모이드 점수 계산
시그모이드 함수는 모든 값을 0~1 사이로 변경해준다. 따라서 각 문장에 긍정 혹은 부정 단어가 아무리 많아도 값을 정규화하는 효과를 갖는다.
import math def sigmoid(x): return 1/(1+math.exp(-x)) newdata['sigmoid'] = newdata.senti_score.apply(sigmoid) - 결과확인
Leave a comment