머신러닝(모형 성능 평가 지표)
평가 지표
회귀(Regression) 평가지표
-
MAE(Mean Absolue Error) : 실제 값과 예측 값의 차이를 절대값으로 변환해 평균한 것이다.
-
MSE(Mean Squared Error) : 실제 값과 예측 값의 차이를 제곱해 평균한 것
-
RMSE(Root Mean) : MSE값은 실제 값과 예측 값의 차이를 제곱 했으므로 실제 오류 평균보다 더 커지는 특성이 있어 MSE에 루트를 씌운것이다. 그리고 MAE에 비해 직관성은 떨어지만 특이값에 대한 강점을 보인다.
-
MSLE(Mean Squared Log Error) : MSE에 로그를 적용해준 지표입니다.
-
RMSLE(Root Mean Squared Log Error) : RMSE에 로그를 적용해준 지표입니다.
-
R^2(R Sqaure) : R^2은 분산 기반으로 예측 성능을 평가합니다. 1에 가까울수록 예측 정확도가 높습니다.(예측값/실제값)
- 예제
import numpy as np
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error, mean_squared_log_error
test = np.array([1,2,3,4,5,6,7,7,8,8,9,9])
pred = np.array([2,2,3,3,5,5,7,7,9,9,8,9])
MAE = mean_absolute_error(test, pred)
# MAE = 0.5
MSE = mean_squared_error(test, pred)
# MSE = 0.5
RMSE = np.sqrt(MSE)
# RMSE = 0.7071067811865476
MSLE = mean_squared_log_error(test, pred)
# MSLE = 0.022604995438044825
RMSLE = np.sqrt(mean_squared_log_error(test, pred))
# RMSLE = 0.15034957744551472
R2 = r2_score(test, pred)
# R2 = 0.9270516717325228
분류모형 평가
아래의 표는 분류모형의 성능을 평가하는데 활용하는 표이다.
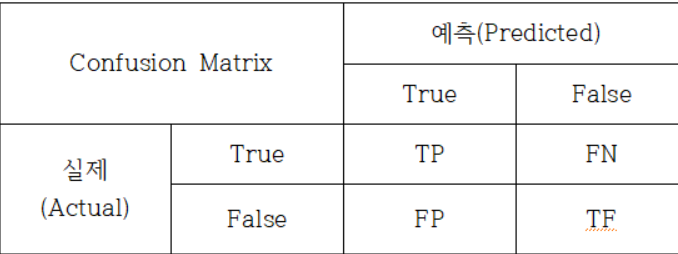
- TP(True Positive): 실제로 True이면서 예측도 True
- TN(True Negative): 실제로 False이면서 예측도 False
- FP(False Positive): 실제로 False인데 예측을 True
- FN(False Negative): 실제로 True인데 예측을 False
-
정확도(Accuracy) : 전체 중 맞춘 예측 비율 “얼마나 잘 맞췄는가” TP + TN / 전체(TP+FN+FP+TN)
-
Recall : 실제로 True인 것 중에 True라고 맞게 예측한 비율 TP / TP + FN
-
정밀도(Precision) : True라고 예측한 것 중에 실제로 True인 경우 TP / TP + FP
-
F1 Score : Precision과 Recall의 가중치 조화 평균으로 Precision과 Recall을 동시에 확일할 때 측정지표로 활용 2 X (Precision X Recall / Precision + Recall)
Leave a comment