머신러닝(차원축소)
Dimensionality Reduction
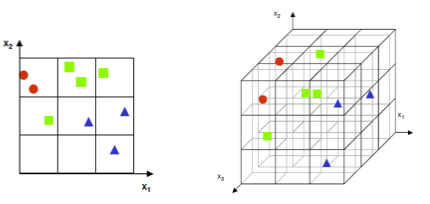
차원 축소는 왜 해야할까요? - 차원의 저주
차원의 저주는 저차원에서는 일어나지 않는 현상들이 고차원에서 데이터를 분석하거나 다룰 때 생겨나는 현상을 말합니다.
고차원으로 올라갈 수록 공간의 크기가 증가하게 되는데, 데이터는 해당 공간에 한정적으로 위치되어 빈 공간이 많아지기 때문에 발생합니다.
이러한 이유로 데이터의 차원이 너무 큰 경우에는 필요없는 변수를 제거하고, 과적합을 방지하기위해 데이터의 차원을 축소합니다.
또는, 사람이 인식할 수 있는 차원은 3차원이 최대이므로 데이터의 시각화를 위해 차원을 축소하기도 합니다.
주 성분 분석 (Principal Component Analysis, PCA)
대표적인 차원 축소 기법으로 주 성분 분석(이하, PCA)이라는 방법이 있습니다.
PCA는 여러 차원으로 이루어진 데이터를 가장 잘 표현하는 축으로 Projection 해서 차원을 축소하는 방식을 사용합니다.
데이터를 가장 잘 표현하는 축이란, 데이터의 분산을 잘 표현하는 축이라고 할 수 있습니다.
기본적으로 주성분(Principal Component, PC)은 데이터 셋을 특이값 분해를 통해 추출된 고유 벡터입니다.
각 고유 벡터들은 서로 직교성을 띄기 때문에 데이터를 주성분로 Projection 시켰을 때 서로 독립적으로 데이터를 잘 표현할 수 있습니다.
PCA의 단점으로는 떨어뜨린 주성분이 어떤 컬럼인지를 설명할 수 없다는 점이 있습니다.
주 성분 분석의 단계
- 각 컬럼들의 값의 범위를 평균과 표준편차를 사용해 정규화시켜 동일하게 만들어줍니다. (스케일링)
- 데이터의 공분산을 계산합니다.
- 공분산 행렬에 대해 특이값 분해를 하여 주성분(고유 벡터)과 고유 값을 얻어냅니다.
- 주성분과 대응되는 고유 값은 주성분이 데이터의 분산을 표현하는 정도의 척도로 사용되므로, 고유 값의 크기와 비율을 보고 몇개의 주성분을 선택할 것인지 또는 원하는 차원의 개수만큼의 주성분을 선택합니다.
- 선택한 주성분으로 모든 데이터를 Projection시켜 데이터의 차원을 축소합니다.
Projection(사영)
Projection에 대해 간단히 짚고 넘어가겠습니다.
벡터 공간에서 어떤 벡터 a와 b가 있을 때 벡터 b를 벡터 a에 사영한 결과(x)는 아래 그림과 같습니다.
벡터 b를 벡터 a에 사영한다는 것은 벡터 a에 대해 수직인 방향으로 벡터 b를 떨어뜨리는 것을 의미합니다.
간단히 말해서, 벡터 b의 그림자를 벡터 a에 떨어뜨린 것을 생각하시면 편합니다.
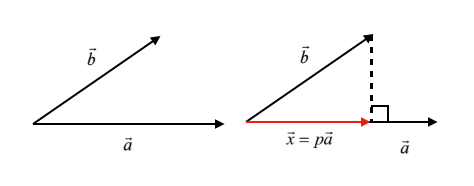
PCA의 기본 원리는 데이터의 분산을 가장 잘 표현하는 벡터(축)를 찾아 해당 벡터에 데이터들을 사영 시키는 것입니다.
-
모델 불러오기 및 정의하기
from sklearn.decomposition import PCA pca = PCA(n_components=2) -
데이터에서 특징 찾기(주 성분 찾기)
pca.fit(data) -
데이터 변환(주 성분으로 데이터 사영하기)
new_data=pca.transform(data)
Categorical Variable to Numeric Variable
이번에는 범주형 변수를 수치형 변수로 나타내는 방법에 대해 알아보겠습니다.
여기에서 범주형 변수란, 차의 등급을 나타내는 [소형, 중형, 대형] 처럼 표현되는 변수를 말합니다.
범주형 변수는 주로 데이터 상에서 문자열로 표현되는 경우가 많으며, 문자와 숫자가 매핑되는 형태로 표현되기도 합니다.
1. Label Encoding
라벨 인코딩은 n개의 범주형 데이터를 0~n-1 의 연속적인 수치 데이터로 표현합니다.
예를 들어, 차의 등급 변수를 라벨 인코딩으로 변환하면 다음과 같이 표현할 수 있습니다.
소형 : 0
중형 : 1
대형 : 2
라벨 인코딩은 간단한 방법이지만, ‘소형’과 ‘중형’이라는 범주형 데이터가 가지고 있는 차이가 0과 1의 수치적인 차이라는 의미가 아님을 주의하셔야 합니다.
Label Encoding과 Sklearn의 preprocessing 패키지에 있습니다.
# 모델 불러오기 및 정의하기
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
#데이터에서 특징 찾기
le.fit(label)
#데이터 변환(범주형 변수를 수치형 변수로)
label_encoded_label = le.transform(label)
#결과 살펴보기
result = pd.DataFrame(data = np.concatenate([label.values.reshape((-1,1)), label_encoded_label.reshape((-1, 1))], axis=1),
columns=['label', 'label_encoded'])
result.head(10)
2. One-hot Encoding
원핫 인코딩은 n개의 범주형 데이터를 n개의 비트(0,1) 벡터로 표현합니다.
예를 들어, 위에서 언급한 소형, 중형, 대형으로 이루어진 범주형 변수를 원핫 인코딩을 통해 변환하면 다음과 같이 표현할 수 있습니다.
소형 : [1, 0, 0]
중형 : [0, 1, 0]
대형 : [0, 0, 1]
원핫 인코딩으로 범주형 데이터를 나타내게되면, 서로 다른 범주에 대해서는 벡터 내적을 취했을 때 내적 값이 0이 나오게 됩니다.
이는 서로 다른 범주 데이터는 독립적인 관계라는 것을 표현할 수 있게 됩니다.
One-hot Encoding은 Sklearn의 preprocessing 패키지에 있습니다.
# 모델 불러오기 및 정의하기
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(sparse=False)
#데이터에서 특징 찾기
ohe.fit(label.values.reshape((-1, 1)))
#데이터 변환(범주형 변수를 수치형 변수로)
one_hot_encoded = ohe.transform(label.values.reshape((-1,1)))
#결과 살펴보기
columns = np.concatenate([np.array(['label']) , ohe.categories_[0]])
result = pd.DataFrame(data = np.concatenate([label.values.reshape((-1,1)), one_hot_encoded.reshape((-1, 3))], axis=1),
columns=columns)
result.head(10)
Leave a comment