머신러닝(데이터전처리)
Scaling
스케일링을 왜 해야할까요?
변수의 크기가 너무 작거나, 너무 큰 경우 해당 변수가 Target 에 미치는 영향력이 제대로 표현되지 않을 수 있습니다.
Sklearn의 대표적인 스케일링 함수로는 특정 변수의 최대, 최소 값으로 조절하는 Min-Max 스케일링과 z-정규화를 이용한 Standard 스케일링이 있습니다.
1. Min-Max Scaling
- Min-Max 스케일링을 하면, 값의 범위가 0 ~ 1 사이로 변경됩니다.
수식을 직관적으로 이해해보면, X에 존재하는 어떤 가장 작은 값 x m에 대해서 x m는 Min(X)의 값과 같습니다.
따라서 스케일링 후 xm은 0이되고, X에 존재하는 어떤 가장 큰 값x M은 분모의 식과 같아지므로 1이됩니다.
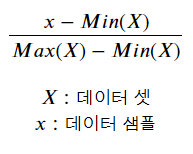
Sklearn에서 Min-Max Scaler는 preprocessing 패키지에 있습니다.
-
data 준비
data = (data - np.min(data)) / (np.max(data) - np.min(data)) -
모델 불러오기 및 정의하기
from sklearn.preprocessing import MinMaxScaler mMscaler = MinMaxScaler() -
데이터에서 특징 찾기
mMscaler.fit(data) -
데이터 변환
mMscaled_data = mMscaler.fit_transform(data)
2. Standard Scaling
z-score 라고 하는 데이터를 통계적으로 표준정규분포화 시켜 스케일링을 하는 방식입니다.
데이터의 평균이 0, 표준 편차가 1이 되도록 스케일링 합니다.
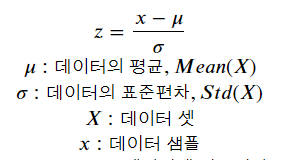
Sklearn에서 Standard Scaler는 preprocessing 패키지에 있습니다.
Sampling
샘플링은 왜 할까요?
먼저 클래스 불균형 문제를 이야기 해보겠습니다.
클래스 불균형 문제란, 분류를 목적으로하는 데이터 셋에 클래스 라벨의 비율이 균형을 맞추지 않고, 한쪽으로 치우친 경우를 말합니다.
이런 경우, 모델이 각 클래스의 데이터를 제대로 학습하기 어려워집니다. 따라서 각 클래스별 균형을 맞추는 작업이 필요합니다.
샘플링은 다음과 같이 크게 두 가지로 나눌 수 있습니다.
- 적은 클래스의 데이터 수를 증가 시키는 Oversampling
- 많은 클래스의 데이터 수를 감소 시키는 Undersampling
1. Random Over, Under Sampling
가장 쉽게 (Over, Under) 샘플링 하는 방법은 임의(Random)로 데이터를 선택하여, 복제하거나 제거하는 방식을 사용할 수 있습니다. 하지만, 이러한 방식은 몇가지 문제점이 있습니다.
- 복제하는 경우, 선택된 데이터의 위치에 똑같이 점을 찍기 때문에 데이터 자체에 과적합될 수 있음
- 제거하는 경우, 데이터셋이 가지고 있는 정보의 손실이 생길 수 있음
샘플링 알고리즘은 클래스 불균형 처리를 위한 imblearn(imbalanced-learn) 라이브러리에 있습니다.
Random Over, Under Sampler는 imblearn 라이브러리의 over_sampling, under_sampling 패키지에 있습니다.
-
모델불러오기 및 정의하기
from imblearn.over_sampling import RandomOverSampler from imblearn.under_sampling import RandomUnderSampler ros = RandomOverSampler() rus = RandomUnderSampler() -
데이터 특징 찾기(데이터 비율) + 데이터 샘플링
# 데이터에서 특징을 학습함과 동시에 데이터 샘플링 # Over 샘플링 oversampled_data, oversampled_label = ros.fit_resample(data, label) oversampled_data = pd.DataFrame(oversampled_data, columns=data.columns) # Under 샘플링 undersampled_data, undersampled_label = rus.fit_resample(data, label) undersampled_data = pd.DataFrame(undersampled_data, columns=data.columns) -
결과 살펴보기
print('원본 데이터의 클래스 비율 \n{}'.format(pd.get_dummies(label).sum())) print('\nRandom Over 샘플링 결과 \n{}'.format(pd.get_dummies(oversampled_label).sum())) print('\nRandom Under 샘플링 결과 \n{}'.format(pd.get_dummies(undersampled_label).sum()))
2. SMOTE(Synthetic Minority Oversampling Technique)
임의 Over, Under 샘플링은 데이터의 중복으로 인한 과적합 문제와 데이터 손실의 문제가 있었습니다.
그런 문제를 최대한 피하면서 데이터를 생성하는 알고리즘인 SMOTE에 대해 알아보겠습니다.
SMOTE의 기본 개념은 어렵지 않습니다. 수가 적은 클래스의 점을 하나 선택해 k개의 가까운 데이터 샘플을 찾고 그 사이에 새로운 점을 생성합니다.
SMOTE의 장점으로는 데이터의 손실이 없으며 임의 Over 샘플링을 하였을 때 보다 과적합을 완화 시킬 수 있습니다.
전복 데이터셋은 SMOTE로 생성되는 데이터 샘플을 살펴보기 어려우므로, 임의의 데이터 샘플을 생성해 살펴보겠습니다.
1000개의 데이터 샘플이 5 : 15 : 80 비율로 되어있으며, 2차원 데이터를 생성합니다
-
모델 불러오기 및 정의하기
from imblearn.over_sampling import SMOTE ## k_neighbors 파라미터로 가까운 데이터 샘플의 수를 결정할 수 있습니다. smote = SMOTE(k_neighbors=5) -
데이터 특징 찾기(데이터 비율) + 데이터 샘플링
smoted_data, smoted_label = smote.fit_resample(data, label) -
결과 살펴보기
print('원본 데이터의 클래스 비율 \n{}'.format(pd.get_dummies(label).sum())) print('\nSMOTE 결과 \n{}'.format(pd.get_dummies(smoted_label).sum()))
Leave a comment